Introduction to Database Schema Design
Introduction
In the realm of software development, databases are the backbone that supports applications by managing data efficiently and securely. A critical component of effective database management is schema design. A well-structured database schema can enhance performance, ensure data integrity, and simplify maintenance, while a poorly designed schema can lead to inefficiencies, data anomalies, and technical debt. This article will introduce you to the fundamentals of database schema design, guiding you through its importance, key concepts, and best practices.
Database Schema
A database schema is a blueprint that outlines the structure of a database. It defines how data is organized and how relationships among data are managed. Schemas include definitions of tables, columns, data types, indexes, and constraints. Essentially, a schema serves as a map for both developers and the database management system (DBMS) to understand the data model.
Importance of Database Schema Design
- Data Integrity: A well-designed schema ensures that the data is accurate and consistent. Constraints such as primary keys, foreign keys, and unique constraints prevent invalid data from being inserted.
- Performance: Efficient schema design can optimize query performance, reducing the time and resources needed to retrieve data.
- Scalability: As applications grow, a good schema design can handle increased load without significant changes.
- Maintainability: Clear and logical schema design makes it easier to understand and modify the database, facilitating smoother development and maintenance processes.
Key Concepts in Schema Design
Entities and Tables:
Entities represent objects or things in the real world, such as customers, products, or orders. In a relational database, entities are represented as tables. An entity is uniquely identifiable. An entity doesn't require a certain function, it just exists.
Attributes and Columns:
Attributes are properties or characteristics of an entity. In a table, attributes are represented as columns.
Primary Keys:
A primary key is a unique identifier for each record in a table. It ensures that each record is distinct and can be referenced unambiguously.
Foreign Keys:
A foreign key is a field in one table that links to the primary key of another table, establishing a relationship between the two tables.
Normalization:
Normalization is the process of organizing data to reduce redundancy and improve data integrity. It involves dividing large tables into smaller, related tables and defining relationships between them.
Indexes:
Indexes are special data structures that improve the speed of data retrieval operations on a database table.
Let’s look at the following example below:
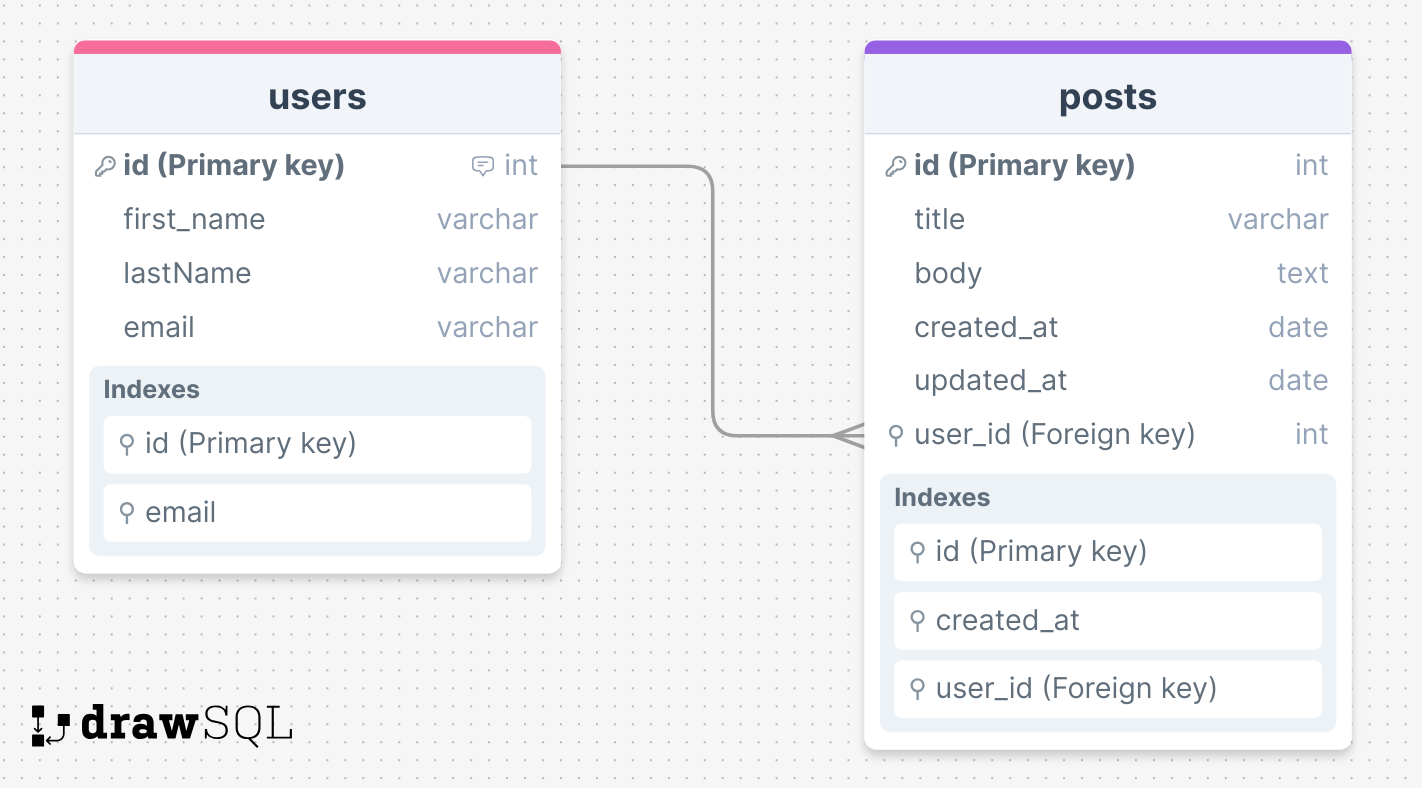
From the figure above, we can clearly see the relationship between two tables Users and Posts.
Users Table
The users table consists of four columns:
- id (Primary Key, int, auto-increment): Uniquely identifies each user.
- first_name (string): Stores the first name of the user.
- last_name (string): Stores the last name of the user.
- email (string): Stores the email address of the user.
Indexes are created on the id and email columns to enable fast retrieval of user records. The id column serves as the primary key, ensuring each user has a unique identifier, while indexing the email column speeds up queries involving email searches.
Posts Table
The posts table consists of six columns:
- id (Primary Key, int, auto-increment): Uniquely identifies each post.
- title (string): Stores the title of the post.
- content (text): Contains the body of the post.
- user_id (Foreign Key, int): Links to the id column in the users table, establishing a relationship between the post and the user who created it.
- created_at (timestamp): Records the timestamp when the post was created.
- updated_at (timestamp): Records the timestamp when the post was last updated.
Indexes are created on the id, created_at, and user_id columns. The id column is the primary key, ensuring each post has a unique identifier. Indexing created_at helps in retrieving posts based on their creation time, and indexing user_id optimizes queries that fetch posts by a specific user.
Relationships
The user_id column in the posts table is a foreign key that links to the id column in the users table. This relationship enforces referential integrity, ensuring that every post is associated with a valid user. In this setup, a single user can create multiple posts, but each post can only belong to one user, reflecting a one-to-many relationship between users and posts.
Best Practices for Schema Design
- Use Meaningful Names: Choose clear and descriptive names for tables, columns, and constraints to make the schema self-explanatory.
- Keep It Simple: Avoid over-complicating the schema. A simple, intuitive design is easier to manage and understand.
- Document the Schema: Maintain comprehensive documentation to help developers understand the structure and logic of the database.
- Consider Future Requirements: Design the schema to accommodate future needs and potential expansions.
- Optimize for Performance: Balance normalization with performance. In some cases, denormalization might be necessary to optimize read-heavy operations.
Some Database Schema Design Tools:
Conclusion
Database schema design is a fundamental aspect of building robust and efficient applications. A well-thought-out schema lays the groundwork for data integrity, performance, and scalability, ultimately contributing to the overall success of the application. By understanding the principles and best practices of schema design, you can create databases that not only meet current requirements but also adapt to future challenges with ease. Happy designing!